Interacting with LLMs
When you type a prompt:
- It gets broken into tokens (e.g., words or parts of words)
- The model uses statistical prediction to generate likely next tokens based on prior context
- Starting a new chat resets its memory
LLMs can only "remember" a limited number of tokens at once, like working within the space of a whiteboard. Too much input, and earlier context gets wiped. Sometimes it's best to start a new chat to refresh the 'working memory'.
tip
Long chats can confuse models. Just like students thrive with clear instructions, the clearer your prompt, the better the model can respond.
Below: words are transformed into tokens
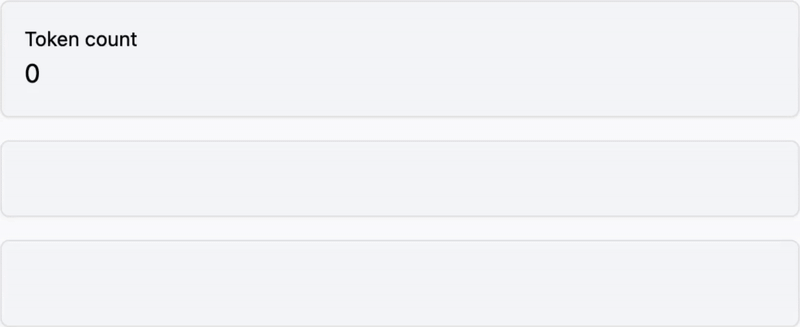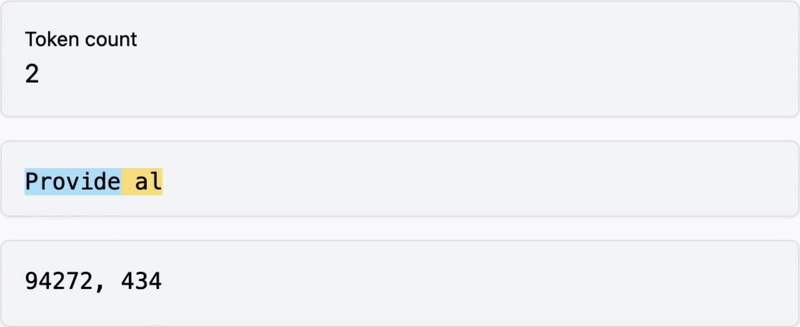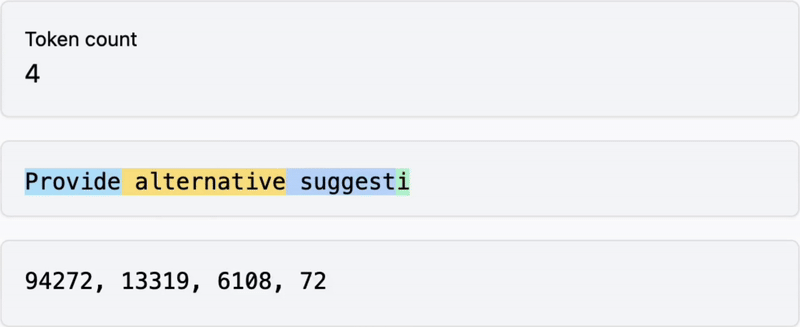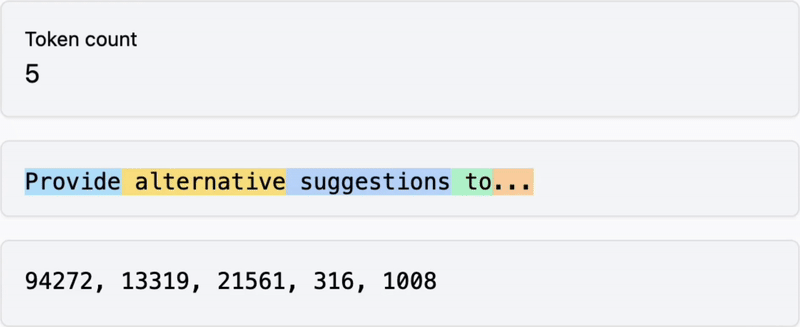 Visit https://tiktokenizer.vercel.app to explore how different tools transform words into tokens.
Visit https://tiktokenizer.vercel.app to explore how different tools transform words into tokens.